
Introduction
Organizations are putting serious effort into their digitalization journey. We keep adding new tools, automating processes, and collecting more data every single day. But despite all of this, there is one constant: our systems and services seem to not work well together! What organizations really want is for systems to connect and share data easily, so we can move faster, make better decisions, and get more out of what we already have.
That is the real goal and purpose of digital transformation!
This post will explore a practical approach to rethinking how your software and services connect. The idea is not to add more tools or rely on custom fixes, but to shift how we think about visibility, integration, and collaboration across systems.
The reality, however, is that the path to achieve this level of smooth collaboration is not easy to see at first. In trying to bridge the gaps between systems, complexity often increases as a consequence. Organizations may turn to middleware as a quick patch, or build custom point-to-point integrations that quickly become difficult and expensive to maintain. This reactive approach not only clutters the IT landscape, but also leads to vendor lock-in and limited flexibility. This is like expanding a building without ever stepping back to consider the architecture!
But this challenge is not entirely new. If we look back at the late 2000s, many early adopters of Service-Oriented Architecture (SOA) faced similar issues. The concept of building independent and reusable components was promising. But in the end, many considered this first wave of adoption a failure, not necessarily because the individual services were flawed, but often due to a lack of a clear strategy for governance, standard integrations, and a connection between design and runtime aspects.
Without a clear strategy, valuable resources become hidden treasures. This leads to duplicate efforts, missed opportunities, and integration nightmares! This served as a critical lesson: having a collection of services is not enough if there is no coherent plan for how they find, understand, and connect with each other.

Solving this challenge is not about silver bullets or shortcuts. It requires a well thought strategy involving supporting systems, and a clear identification of information sources. But it also takes a change in mindset, where data and services are not just built, but made discoverable, understandable, and ready to be reused. So how can we move toward that kind of environment? How do we find what we need, when we need it? And what would it mean if discovery was not an afterthought, but a core capability helping our systems work?
Change how you do development: Let Systems Do Discovery
Our challenge is clear: many organizations have valuable data and useful services, but actually getting them to work together effectively can be a real struggle. We discussed how past attempts often lost momentum due to a lack of a clear structure, and promised to explore a more structured approach to liberate these assets. The first key step in that strategy is discovery. A robust discovery strategy is not just a fancy add-on, it is critical for building flexible and resilient systems.
Even in older, large monolithic applications, finding the right piece of code or understanding how to reuse existing functionality was often an internal challenge, even if it was all in a single codebase. This made so that someone in their time of need would rewrite an existing functionality, making these monoliths increasingly complex and difficult to maintain. Breaking up monoliths into microservices did not eliminate the challenge of finding code pieces, instead it just moved it outside the codebase, making it even harder and more crucial to solve.
Just telling developers that the service they need is on a specific endpoint, hardcoding an IP address, or even worse, connecting two systems directly in the source code with close to no documentation about it, is a recipe for disaster. Systems built that way are brittle, they break easily when things change, and they are hard to update and scale.
One of the reasons the architectural paradigms changed was in favor of principles such as loose coupling and late binding. To achieve those properties, the components within a system should provide capabilities without assuming who will consume them. In the same way, consumers do not need to know specific service locations, instead, by using discovery, the connections should be resolved as late as possible, ideally at runtime, based on configuration or deployment context.
But how can connections between passive components be established in a dynamic landscape? This is just the void that a registry would fill, in this case a Service Registry. It provides a central directory of available systems, allowing systems to resolve connections based on identities and contracts.
Identify each information source - Make them discoverable!
All in all, these principles allow IT operation teams to control how services are composed and which service instances are used, without modifying application code!
Drawing the Maps - Enabling Data Availability
As I said before, in a large ecosystem, it is not enough to simply list services, which are capabilities you can call to perform an action or return processed data. If you have hundreds of data sources and services listed, it is still like trying to find a specific tool in a massive disorganized toolbox. To make discovery effective, we need some mechanism to describe both what a service does and how to interact with it. That is where the concept of a service identity and an API specification identifier becomes relevant.
The service identity describes the capability a service provides, often linked to a particular information object, such as an OrderProcessingService that works with order data. This refers to what the service does, not to the system or application where it runs.
The API specification identifier, on the other hand, points to the contract that defines how the interface works. It includes information such as which operations the service supports, what data it accepts, what protocol it uses, or how the response from the service looks like. This identifier act as a reference to an interface definition document, such as an OpenAPI or AsyncAPI file. An example of this could be OrderProcessingService_HTTP_V1.2.0.
All these concepts create a bridge between design-time, implementation-time, and run-time. In this way, whatever is planned during architectural discussions is reflected faithfully in development and operation.
Published Contracts Don’t Change (They Get Versioned!)
Because these API Specification contracts are promises, they need to be stable. This is where versioning becomes critical. The goal is that both consumers and providers know exactly what to expect, even during development phases. This stability helps independently developed systems to interoperate without constant coordination.
There is much more to say about managing the lifecycle of these specifications, including how updates, deprecations, and breaking changes should be handled. Those are important topics, but they are outside the scope of this post. For now, the key point is this: once a contract is published and in use, it does not change!
A Discovery & Utilization Workflow in Action
It is time to go through with how these concepts (registries, identities, and contracts) are used together to enable discovery of services and their information.
Let's picture a factory floor that operates a fleet of robotic arms from different vendors. These machines expose interfaces for both monitoring and control, such as temperature reporting or pause and resume commands.
As we discussed previously, these systems should not have hardcoded addresses for every service they need. Instead, the workflow the automation layer should take to use the machine's services could look like this:
- The automation system need to monitor machine temperatures. It already supports the interface
TemperatureSensor_HTTP_v1.0, so it queries the central service registry asking for services that implement that API specification.
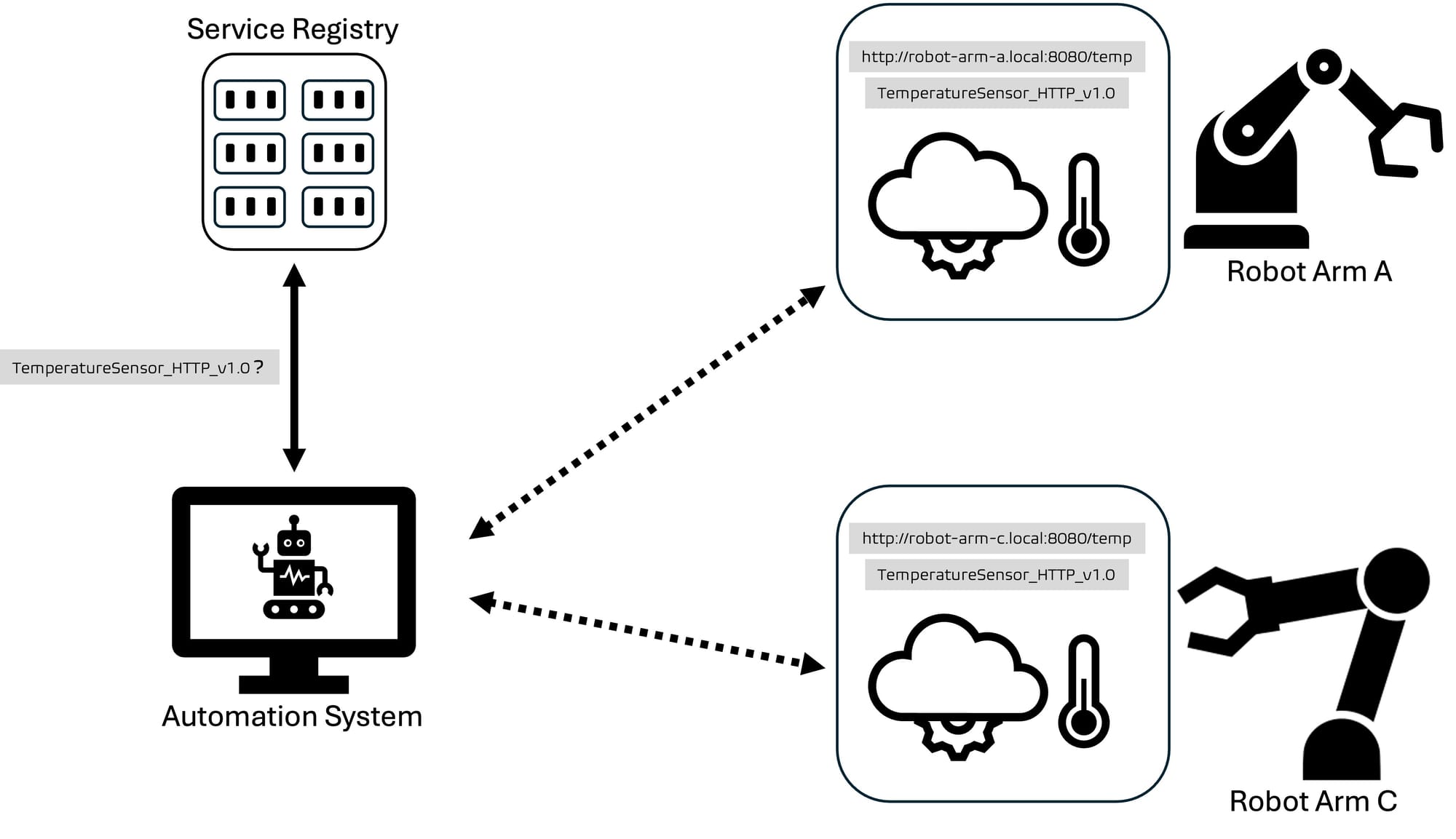
- The registry responds with a list of compatible services. These are all machine endpoints that expose temperature data using the expected interface.
TemperatureSensorRobotArm_Aathttp://robot-arm-a.local:8080/tempTemperatureSensorRobotArm_Cathttp://robot-arm-c.local:8080/temp
- The automation system can collect temperature data from the available services, since it already knows how to interpret the response format defined by the
TemperatureSensor_HTTP_v1.0contract, and it knows the contact information for each of the interfaces. - If the system detects an anomaly, it may need to send a pause command to all the available machines. It queries the service registry again, but this time looking for a
MachineControl_MQTT_v3.2interface, getting a response like this:
RobotArmA_Controlathttp://robot-arm-a.local:8120/controlRobotArmC_Controlathttp://robot-arm-c.local:8120/control
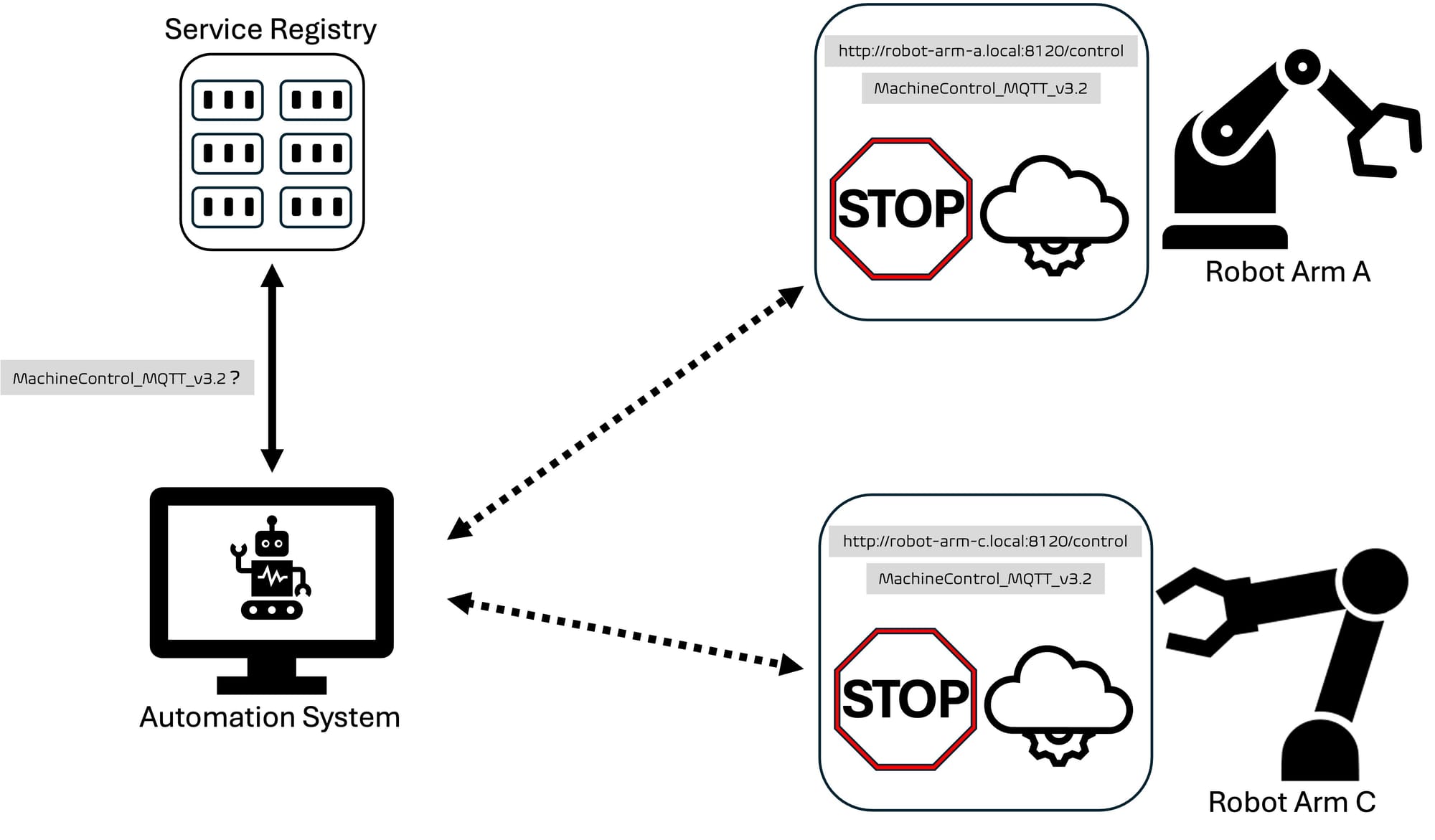
- The system can send a pause command using the structure defined in the shared API contract. The machine pauses its operation as expected, no matter who built it.
What Just Happened?
The central automation system successfully used the discovery mechanism to:
- Request services based on specific API specification identifiers it already supports.
- Receive only those service instances that are fully compatible, without needing to compare protocols or inspect interfaces.
- Connect directly to the selected endpoints and interact confidently, using a shared contract that defines exactly how communication works.
- React to live machine conditions and trigger operational commands, all without hardcoded addresses or vendor-specific logic.
The Human Aspect: ‘Ways of Working’ for Effective Discovery
We have got the tech concepts down: registries, identities, and contracts. This provides the technical foundations, but having all the tools does not guarantee success. To make all of this actually work day-to-day, we need to talk about Ways of Working. There are some aspects that an organization should be on the look for, including but not limited to:
- Designing Contracts First: Do your teams agree on the API or data schema before they start coding? And can everyone find and access those contracts?(Hint: They should!)
- Making Registration Automatic: Is registering a new service or data source a mandatory, maybe even automated, part of your deployment process?
- Looking Before You Leap: Do developers check the registries for existing solutions before building something new?
- Treating Contracts as Law: Is there a shared understanding that published contract versions are sacred and changes always mean new versions?
- Clear Ownership: Does every service and dataset have a clear owner who's responsible for its quality and lifecycle?
- Talking to Each Other: Are there good feedback loops between the people building services and the people using them?
Each of these points are a deep topic in itself, covering everything from team culture and processes to CI/CD pipelines and governance. This is not the blog post where all this gets unpacked, but consider this your heads-up: technology alone will not save you. Without strong ways of working, all you have is what we started with, a growing collection of systems that never truly work well together.
Some final words
In this post we discussed the core idea behind discovering services and data sources, but there is still a lot more to explore. If these topics interest you, make sure to stay tuned for the next Parus Integration posts!
